北京宽带网(www.bbn.com.cn)上的上网记录能不能删除
不能吧,这个应该是网通公司决定的,自己好像在网上是删不了的,可以去网通营业厅咨询下
RMBbn是什么意思?貌似是一种单位!
人民币吧追问
那后面的bn是什么意思呀?这才是关键!追答
bn是book number吧,可能是人民币那个序列号吧
电子商务与互联网的区别
电子商务是依附于互联网。
仅此形式不同:
1、电子商务是指以信息网络技术为手段,以商品交换为中心的商务活动。
2、互联网,又称国际网络,属于传媒领域。
电子商务是指以信息网络技术为手段,以商品交换为中心的商务活动;也可理解为在互联网、企业内部网和增值网上以电子交易方式进行交易活动和相关服务的活动,是传统商业活动各环节的电子化、网络化、信息化;以互联网为媒介的商业行为均属于电子商务的范畴。
互联网,指的是是网络与网络之间所串连成的庞大网络,这些网络以一组通用的协议相连,形成逻辑上的单一巨大国际网络。互联网始于1969年美国的阿帕网。

扩展资料:
电子商务是因特网爆炸式发展的直接产物,是网络技术应用的全新发展方向。以互联网为依托的“电子”技术平台为传统商务活动提供了一个无比宽阔的发展空间,其突出的优越性是传统媒介手段根本无法比拟的。
因特网始是美军在ARPA(阿帕网,美国国防部研究计划署)制定的协定下,首先用于军事连接,后将美国西南部的加利福尼亚大学洛杉矶分校、斯坦福大学研究学院、UCSB(加利福尼亚大学)和犹他州大学的四台主要的计算机连接起来。
这个协定由剑桥大学的BBN和MA执行,在1969年12月开始联机。
参考资料来源:百度百科——电子商务
百度百科——互联网
网络营销经理 网站策划人 SEM主管私信TA
不存在有区别,电子商务是依附于互联网的。
1、电子商务
电子商务是指在因特网开放的网络环境下,买卖双方在任何可联接网络的地点间进行各种商务活动,实现两个或多个交易者间的生产资料交换及所衍生出来的交易过程、金融活动和相关的综合服务活动的一种的商业运营模式。
也就是说电子商务是在互联网下衍生出来一种交易模式。
而假如没有现在的一些先进的互联网通信技术,就不可能存在有电子商务这一说法了。
2、互联网
互联网,又称因特网。是网络与网络之间所串连成的庞大网络,这些网络以一组通用的协议相连,形成逻辑上的单一巨大国际网络。
上面说到互联网与电子商务并不存在有区别,其实互联网是一个大类,它包括所有的网络通信技术。如:电脑与电脑之间的相互通信、手机与手机的相互通信等。
互联网的发展给人们带来许多便利,人们可以不出门就能购买到实体店里的所有商品。而这种购买模式就叫做电子商务。一切以互联网为媒介的交易方式都可称之为电子商务。
3、电子商务的交易方式
电子商务交易模式分为B2B、B2C、C2C、O2O等。
B2B为企业对企业。具有交易金额大、次数少等特性。
B2C为企业对个人。企业通过在互联网上的平台发布商品供个人消费者购买。
C2C为个人对个人。个人消费者和个人消费者之间的交易模式。
O2O为线下和线上相结合的交易模式。让线上成为线下的前锋,通过线上获取客户,线下成交。
移动互联网是移动和互联网融合的产物,继承了移动随时随地随身和互联网分享、开放、互动的优势,是整合二者优势的“升级版本”,即运营商提供无线接入,互联网企业提供各种成熟的应用。互联网创造了经济神话。我们在思考:一个国家的创新能力,最终是这个国家所掌握的创新的技术在市场竞争中的表现。市场才是衡量创新价值的主要标准,而企业应是国家创新能力的主要体现者。推而广之,如果在7亿手机用户这样一个消费群体上建立一个平台,使之广泛应用到企业、商业和农村之中,是否会创造更惊天动地的奇迹?移动互联网是一个全国性的、以宽带IP为技术核心的,可同时提供话音、传真、数据、图像、多媒体等高品质电信服务的新一代开放的电信基础网络,是国家信息化建设的重要组成部分。电子商务是利用微电脑技术和网络技术进行的商务活动。各国政府、学者、企业界人士根据自己所处的地位和对电子商务参与电子商务的角度和程度的不同,给出了许多不同的定义。但是,电子商务不等同于商务电子化。电子商务即使在各国或不同的领域有不同的定义,但其关键依然是依靠着电子设备和网络技术进行的商业模式,随着电子商务的高速发展,它已不仅仅包括其购物的主要内涵,还应包括了物流配送等附带服务。电子商务包括电子货币交换、供应链管理、电子交易市场、网络营销、在线事务处理、电子数据交换(EDI)、存货管理和自动数据收集系统。在此过程中,利用到的信息技术包括:互联网、外联网、电子邮件、数据库、电子目录和移动电话。首先将电子商务划分为广义和狭义的电子商务。广义的电子商务定义为,使用各种电子工具从事商务活动;狭义电子商务定义为,主要利用 Internet从事商务或活动。无论是广义的还是狭义的电子商务的概念,电子商务都涵盖了两个方面:一是离不开互联网这个平台,没有了网络,就称不上为电子商务;二是通过互联网完成的是一种商务活动。狭义上讲,电子商务 (Electronic Commerce,简称 EC)是指:通过使用互联网等电子工具(这些工具包括电报、电话、广播、电视、传真、计算机、计算机网络、移动通信等)在全球范围内进行的商务贸易活动。是以计算机网络为基础所进行的各种商务活动,包括商品和服务的提供者、广告商、消费者、中介商等有关各方行为的总和。人们一般理解的电子商务是指狭义上的电子商务。广义上讲,电子商务一词源自于Electronic Business,就是通过电子手段进行的商业事务活动。通过使用互联网等电子工具,使公司内部、供应商、客户和合作伙伴之间,利用电子业务共享信息,实现企业间业务流程的电子化,配合企业内部的电子化生产管理系统,提高企业的生产、库存、流通和资金等各个环节的效率。联合国国际贸易程序简化工作组对电子商务的定义是:采用电子形式开展商务活动,它包括在供应商、客户、政府及其他参与方之间通过任何电子工具。如EDI、Web技术、电子邮件等共享非结构化商务信息,并管理和完成在商务活动、管理活动和消费活动中的各种交易。
电子商务通常是指是在全球各地广泛的商业贸易活动中,在因特网开放的网络环境下,基于浏览器/服务器应用方式,买卖双方不谋面地进行各种商贸活动,实现消费者的网上购物、商户之间的网上交易和在线电子支付以及各种商务活动、交易活动、金融活动和相关的综合服务活动的一种新型的商业运营模式。 互联网,即广域网、局域网及单机按照一定的通讯协议组成的国际计算机网络。互联网是指将两台计算机或者是两台以上的计算机终端、客户端、服务端通过计算机信息技术的手段互相联系起来的结果,人们可以与远在千里之外的朋友相互发送邮件、共同完成一项工作、共同娱乐。 希望我的回答对您有帮助!
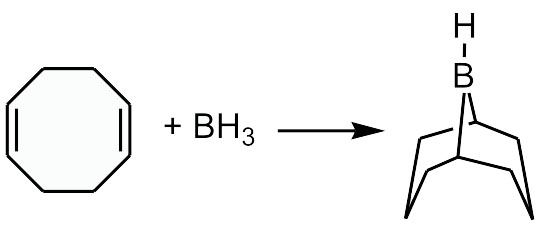
9-BBN的介绍
9-BBN应用较为广泛,是常用的选择性硼氢化试剂,与烯烃反应有较高的选择性,只与位阻较小的双键反应。9-BBN不能以单体形式存在,在极性溶剂,特别是路易斯碱,如THF、(CH3)2S中以单体形式存在或以二聚体形式存在。9-BBN DIMER(9-BBN 二聚体)为白色晶体,性质稳定。二聚体比单体更容易保存和运输,反应后无副产物。
谁有金融数据挖掘,关联规则分析与挖掘的一些介绍啊
金融数据挖掘案例教学:VaR的定义、计算与应用目前,金融资产市场风险(也包括信用风险和操作风险)的通用度量工具为Value at Risk(VaR,在险价值),在几个巴塞尔协议形成后,用VaR度量金融风险更是受到普遍关注。建立金融风险的准确的VaR度量很不容易,本案例通过美元指数市场风险VaR度量模型的建立、及不同VaR模型对银行监管资本要求的影响展开研究,通过案例对VaR的定义、计算与应用作较全面的介绍。一、 VaR的定义设在某一持有期时金融资产的收益率的分布函数为 ,密度函数为 ,对给定的置信水平 ,在险价值的定义为:VaR的含义:VaR是一定置信水平下,一定持有期中,金融资产可能遭受的最大损失。由于VaR与收益率的分布函数(密度函数)密切相关,特别是与分布函数(密度函数)的尾部性质密切相关,因此VaR模型的准确与否就与我们对金融资产收益率过程的描述的准确与否、特别是与收益率过程的尾部特征的描述的正确与否密切相关。由于这种描述很困难,因此建立准确的VaR模型是很不容易的。二、单一资产(资产组合)的VaR模型的构建方法1、 历史模拟法基本思想:金融资产收益率的变化具有某种稳定性,因此可以用过去的变化情况对未来进行预测。案例1:基于历史模拟法的那斯达克指数的VaR模型的构建,取置信水平为0.99与0.95。计算2004年度单位货币的那斯达克指数的每日在险价值,并实际检验模型的预测准确性。数据:那斯达克指数的每日收盘价的收益率时间跨度:19850711~20050923共5115个日收益率数据,收益率采用对数收益率。方法:取300个数据的移动窗口,对每个窗口数据排序后取第3个(第15个)数据作为VaR预测值,窗口移动250次,则可以得到250日中的每日VaR预测值。Sas程序:初始数据库为sjkData a; set sjk ; run;Data a; modify a; if _n_>300 then remove;Run;Proc sort data=a;by r; run;Data a; modify a; if _n_<3 or _n_>3 then remove; run;Data b; set c a;run;Data c; set b; run;Data sjk; modify sjk; if _n_=1 then remove; run;历史模拟方法的缺陷分析VaR模型预测准确性的检验方法(事后检验方法)置信水平0.99,如果模型准确,则例外发生应该服从 , 的二项分布。如果例外数为 ,只要计算 就可知道模型是否高估风险;只要计算 就可知道模型是否低估风险。Sas程序Data a; X=probbnml(0.01,250,k);Y=1-probbnml(0.01,250,k-1);run;历史模拟方法通常存在高估风险价值的缺陷,尤其当显著性水平取的很高时,对银行来说,这会提高监管资本要求。从理论上看,历史模拟法也有很大缺陷。2、 参数方法假设 具有某种形式的分布,其中参数需要估计,利用VaR的定义得到VaR预测值。参数方法建立VaR模型是最常见形式,例如J.P.摩根公司开发的Riskmetrics就是采用参数方法。首先想到假设收益率服从正态分布,只要估计均值与标准差,就可得到VaR预测值。如果 ,则 利用正态分布计算在险价值的方法①、利用移动窗口方法计算每个窗口对应的均值与标准差;②、利用均值与标准差得到每日的VaR预测值。③、巴塞尔协议要求用一年的数据计算VaR,我们用一年数据构造移动窗口。案例2:基于参数方法和正态分布假设的那斯达克指数的VaR模型的构建,置信水平为0.99与0.95。计算2000年度单位货币的那斯达克指数每日的在险价值,并实际检验模型的预测准确性。Sas程序(数据库sjk,为简洁起见,只用收益率数据)Data a; set sjk ; run;Data a; modify a; if _n_>254 then remove;Run;Proc means data=a;Output out=b mean=mr std(r)=stdr;run;Data b1; set c b;run;Data c; set b1; run;Data sjk; modify sjk; if _n_=1 then remove; run;Data c1;set c;Var=2.33*stdr-mr; run;对模型预测的检验结果:在252个观测值中有11个例外,模型存在低估市场风险的现象。那么为什么会出现这样的现象。3、 金融资产收益率的特征分析金融资产收益率通常存在两个显著的特征:①、波动的时变性、或者说波动的集聚性,比较那斯达克指数的收益率图形与正态分布的图形可以明显地看到这一点; data a; set sjk;z=normal(17); z1=_n_; run;由于波动具有时变性,因此正态假设不合适,或者说对标准差的估计方法不合适。比较合理的改进方式是,在估计分布的方差时,近期数据应该具有更大的权重。J.P.摩根公司采用加权方式估计方差,一般的方差估计表达式为: 即在估计方差时,每个离差具有相同的权重1/254,而J.P.摩根公司采用的方差估计式为: 如在Riskmetrics中取 。 案例3:建立基于加权正态模型的那斯达克指数的VaR,置信水平为0.99与0.95。计算2000年度单位货币的那斯达克指数每日的在险价值,并检验模型的预测准确性。原始数据库sjk,均值数据库aa,权重数据库bbSas程序(sjk)Data a; set sjk;run;Data a; modify a;if _n_>254 then remove;run;Data a1; set aa; run;Data a1; modify a1; if _n_>254 then remove; run;Data c1; merge a a1 bb; run;Data b1; set c1; r1=q*(r-mr)**2; run;Proc means data=b1;Output out=b mean(r1)=mr1; run;Data c2; set c b; run;Data c; set c2; run;Data sjk; modify sjk; if _n_=1 then remove;run;Data aa; modify aa; if _n_<255 then remove; run;Data cc; set c; Stdr1=sqrt(254*mr1); run;检验结果:例外数为7个,模型为“不准确模型”②、金融资产收益率分布的厚尾性,比较那斯达克指数的收益率数据的经验分布的尾部与正态分布的尾部,可以明显地看到这一点。Data a; set sjk;P=probnorm((r+0.000154)/0.0256);run;利用1999-2001年度的数据,可以看到明显的厚尾现象.利用参数方法建立VaR模型时,应该考虑两个因素:波动的时变性与厚尾性.要提高VaR模型的预测准确性,就要采用适当的统计模型来描述收益率的波动特征,模型既要能够反映波动的时变性、又要能够反映波动的厚尾性。现有研究对前一个特征考虑较多,通常的方式是采用GARCH模型(广义自回归条件异方差模型)来描述收益率过程。GARCH模型是Bollerslev(1986)提出的,GARCH模型是对ARCH模型的拓展。假设收益率服从 阶自回归模型,即 ,Bollerslev对 的假设是 。GARCH模型可用较少的参数捕捉方差的缓慢变化。在建立VaR模型时,通常采用的是GARCH(1,1)模型,其形式为 许多研究者在建立描述收益率的统计模型过程中,假设 ,甚至假设 ,这是不合适的(方差过程设置错误不会影响均值过程,而均值过程设置错误会影响方差过程)。因此,应该首先需考虑均值过程,再考虑方差过程。许多实证研究显示,采用GARCH(1,1)模型描述收益率过程可以提高VaR的预测精度,这是因为与正态假设相比,GARCH(1,1)模型能够更好地描述收益率过程,但是实证研究同时发现,当置信水平较高时(如0.99),采用GARCH(1,1)模型建立的VaR模型仍然存在低估风险的现象。原因分析:事件风险造成价格的暴涨暴跌,这是波动过程出现厚尾现象的重要原因,而GARCH(1,1)模型不能反映由事件风险造成的暴涨暴跌,因此不能完全反映厚尾现象,这就造成模型对风险的低估。波动过程不是由一个统计模型描述,而是由两个模型所描述——体制转换模型。对收益率数据的自相关-偏自相关分析的方法sas程序proc autoreg data=a;model r=t / dw=10 dwprob; run;也可以采用Eviews软件进行分析quick/series tatistics/corrlogramGARCH模型参数估计方法Quick/estimation equation /选择ARCH,输入被解释变量名,/options 选择Heteroskedasticity 可得到稳健的标准差连续计算GARCH模型中的时变的方差sas程序data b; set a;z=w+a1*x+b1*lag(y);run;data b; modify b;if _n_<2 or _n_>2 then remove; run;data b1; set c b; run;data c; set b1; run;data b1; set b; y=z; run;data b; set b1; run;data a; modify a; if _n_<3 then remove; run;data b1; set b a; run;data a; set b1; run;注意:数据库为A,结构为 对于 可按照 计算补充知识: ARCH与GARCH模型一、 阶自回归模型随机过程可分为平稳过程与非平稳过程。平稳过程的均值、协方差不随时间变化。自回归模型是对平稳过程产生的时间序列进行建模的方法。1、 阶自回归模型有效市场假设 是独立过程,实际上 存在自相关性,如果存在 阶自相关, 可用如下形式表示: ,其中 与 相互独立、服从独立同分布的正态分布。2、移动平均模型如果 为它的当前与前期随机误差项的线性函数,即 ,则称时间序列 为移动平均序列。3、自回归移动平均过程 。4、自相关与偏自相关对时间序列进行建模,首先需判断其服从什么过程。这就涉及自相关、偏自相关的概念,k阶自相关系数定义为: 。k阶偏自相关系数的定义:偏自相关是指在给定 的条件下, 与 的条件相关关系。其计算式为: , 。二、模型的识别1、自回归模型的识别自回归模型 的偏自相关系数是 步截尾的,而其自相关系数则呈指数或正弦波衰减,具有拖尾性;平均移动模型 的自相关系数是 步截尾的,而其偏自相关系数则呈指数或正弦波衰减,具有拖尾性。自回归平均移动过程的自相关系数、偏自相关系数均呈指数或正弦波衰减,具有拖尾性。2、模型识别的例利用2002年度美元指数收盘价的对数收益率数据a1、2002年度那斯达克指数收盘价的对数收益率数据b1分别判断其所满足的模型。计算自相关系数、偏相关系数的Eviews方法:quick / series statistics / correlogram / r利用GDP数据c1进行模型识别由于其一阶自相关系数、前二阶的偏自相关系数显著地不等于零,可建立自回归移动平均模型ARMA(2,1)。即 ARMA(2,1)模型参数估计的Eviews方法Qick/Estimate Equation/rr ar(1) ar(2) ma(1)注意在时间序列模型分析中,对参数的t检验不像一般回归模型中那样重要,主要是考虑模型整体的拟合效果。三、ARCH与GARCH模型在自回归模型中假设时间序列由平稳过程产生,即产生时间序列的随机过程具有不随时间变化的均值与标准差。实际上,由于金融资产收益率具有波动的时变性,即产生时间序列的随机过程的二阶矩随时间而变化,因而随机过程不是一个平稳过程,不适合直接采用以上的分析方法。现在需要建立自回归条件异方差模型(ARCH模型)和广义自回归条件异方差模型(GARCH模型)。1、ARCH模型该过程由Engle(1982)发展起来,目的是解决随时间而变化的方差问题。它经常用于对金融资产的收益率的波动性进行建模。假设收益率服从 阶自回归模型,即 , 服从均值为0,方差为 的正态分布, 取决于 过去值的平方。 阶自回归条件异方差模型ARCH( )的形式 ,其中 为未知的正系数。在ARCH模型中, 随时间而变化,如果近期平方误差很大,则当前平方误差也会较大,即 为较大;反之,如果近期平方误差很小,在当前平方误差也会较小;通过这种方式表示波动的集聚性。2、GARCH模型Bollerslev(1986)提出的GARCH模型扩展了ARCH模型,假设收益率服从 阶自回归模型,即 ,Bollerslev对 的假设是 与ARCH模型相比,GARCH模型可以利用更少的参数捕捉到方差的缓慢变化。从理论上讲,由于不同金融资产收益率的波动布变性不同,因此某种资产收益率究竟服从哪种GARCH也需要进行判别,实际上,很多金融资产的收益率服从GARCH(1,1)模型,即 。注意这个式子表明,第t天的方程 由第t-1天的二个值 决定,其中残差 的估计值为 ,而 可递推得到。特别地有 。利用这样的方式计算方差,实际上隐含着假设,方差的波动方式在训练时期与计算时期是一致的。由于在对收益率建立GARCH(1,1)模型时,自回归模型的准确设置与否会直接影响到GARCH模型的参数估计,因此必须正确建立均值过程再建立方差过程。3、GARCH模型的参数估计方法如果金融资产的收益率服从p阶自回归及GARCH(1,1)过程,则Eviews方式为quik / Estimate Equation例: n1给出那斯达克收盘价的对数数据,试用适当的方式建立模型。解:股票市场一般服从随机游走过程,但是其方差具有波动性,因此lp lp(-1)出的哪本《金融数据挖掘》你也买来自己看看
接分啦。。。找到一篇不错的文章楼主看下,参考资料:http://blog.csdn.net/ctu_85/archive/2008/09/16/2937486.aspx2.关联规则挖掘过程、分类及其相关算法2.1关联规则挖掘的过程关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(Frequent Itemsets),第二阶段再由这些高频项目组中产生关联规则(Association Rules)。关联规则挖掘的第一阶段必须从原始资料集合中,找出所有高频项目组(Large Itemsets)。高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一水平。一项目组出现的频率称为支持度(Support),以一个包含A与B两个项目的2-itemset为例,我们可以经由公式(1)求得包含{A,B}项目组的支持度,若支持度大于等于所设定的最小支持度(Minimum Support)门槛值时,则{A,B}称为高频项目组。一个满足最小支持度的k-itemset,则称为高频k-项目组(Frequent k-itemset),一般表示为Large k或Frequent k。算法并从Large k的项目组中再产生Large k+1,直到无法再找到更长的高频项目组为止。关联规则挖掘的第二阶段是要产生关联规则(Association Rules)。从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小信赖度(Minimum Confidence)的条件门槛下,若一规则所求得的信赖度满足最小信赖度,称此规则为关联规则。例如:经由高频k-项目组{A,B}所产生的规则AB,其信赖度可经由公式(2)求得,若信赖度大于等于最小信赖度,则称AB为关联规则。就沃尔马案例而言,使用关联规则挖掘技术,对交易资料库中的纪录进行资料挖掘,首先必须要设定最小支持度与最小信赖度两个门槛值,在此假设最小支持度min_support=5% 且最小信赖度min_confidence=70%。因此符合此该超市需求的关联规则将必须同时满足以上两个条件。若经过挖掘过程所找到的关联规则「尿布,啤酒」,满足下列条件,将可接受「尿布,啤酒」的关联规则。用公式可以描述Support(尿布,啤酒)>=5%且Confidence(尿布,啤酒)>=70%。其中,Support(尿布,啤酒)>=5%于此应用范例中的意义为:在所有的交易纪录资料中,至少有5%的交易呈现尿布与啤酒这两项商品被同时购买的交易行为。Confidence(尿布,啤酒)>=70%于此应用范例中的意义为:在所有包含尿布的交易纪录资料中,至少有70%的交易会同时购买啤酒。因此,今后若有某消费者出现购买尿布的行为,超市将可推荐该消费者同时购买啤酒。这个商品推荐的行为则是根据「尿布,啤酒」关联规则,因为就该超市过去的交易纪录而言,支持了“大部份购买尿布的交易,会同时购买啤酒”的消费行为。从上面的介绍还可以看出,关联规则挖掘通常比较适用与记录中的指标取离散值的情况。如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。2.2关联规则的分类按照不同情况,关联规则可以进行分类如下:1.基于规则中处理的变量的类别,关联规则可以分为布尔型和数值型。布尔型关联规则处理的值都是离散的、种类化的,它显示了这些变量之间的关系;而数值型关联规则可以和多维关联或多层关联规则结合起来,对数值型字段进行处理,将其进行动态的分割,或者直接对原始的数据进行处理,当然
http://blog.csdn.net/ctu_85/archive/2008/09/16/2937486.aspx
2009年从事电脑行业至今私信TA
去看看http://baike.baidu.com/view/7893.htm希望对你有帮助